-
 AI
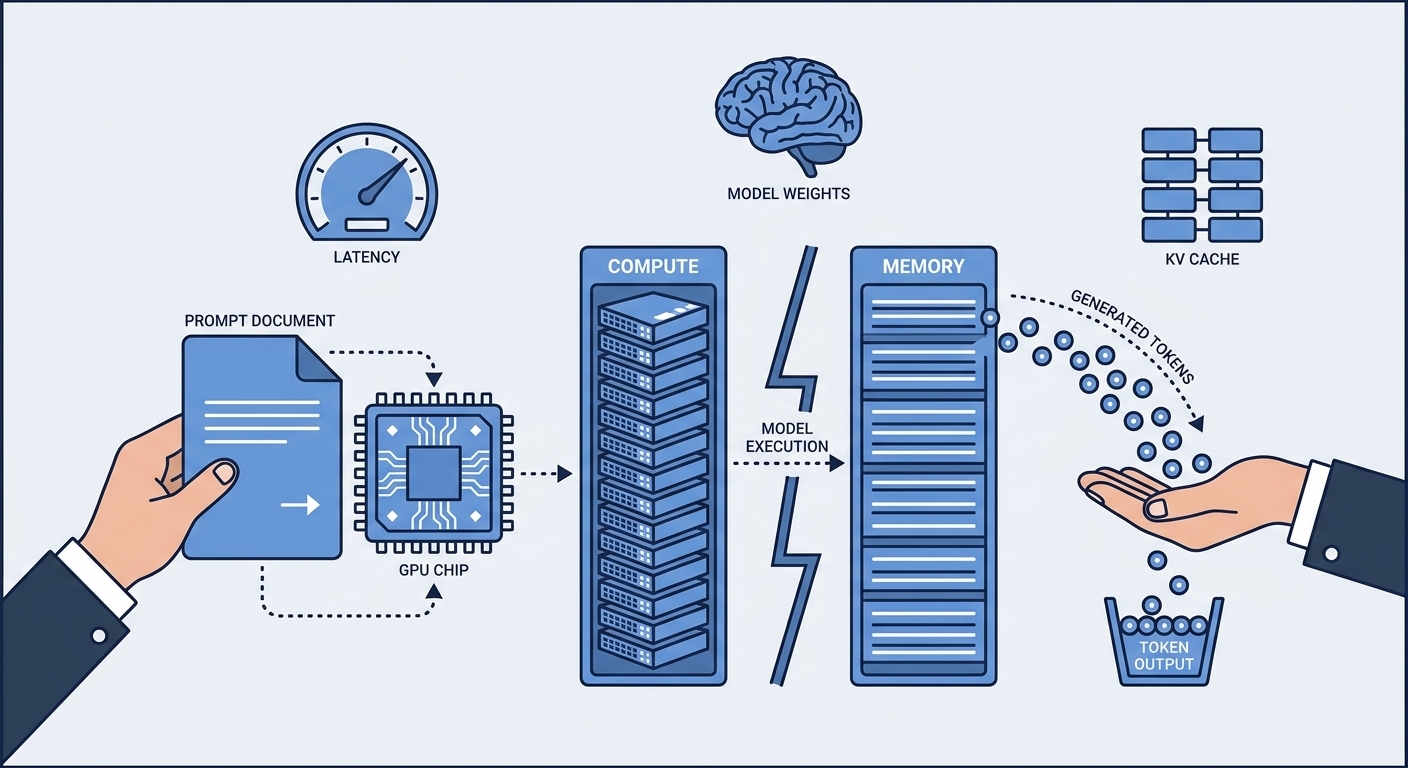
AITwo Workloads in a Trench Coat: Why Prefill and Decode Change Everything
LLM inference is two opposite workloads — compute-bound prefill and memory-bandwidth-bound decode. Here's how continuous batching, PagedAttention, and disaggregation evolved to deal with it.
#llm-inference #prefill-decode #vllm #pageattention #continuous-batching #gpu-architecture #nvidia-dynamo #kv-cache #ai-engineering -
 AI
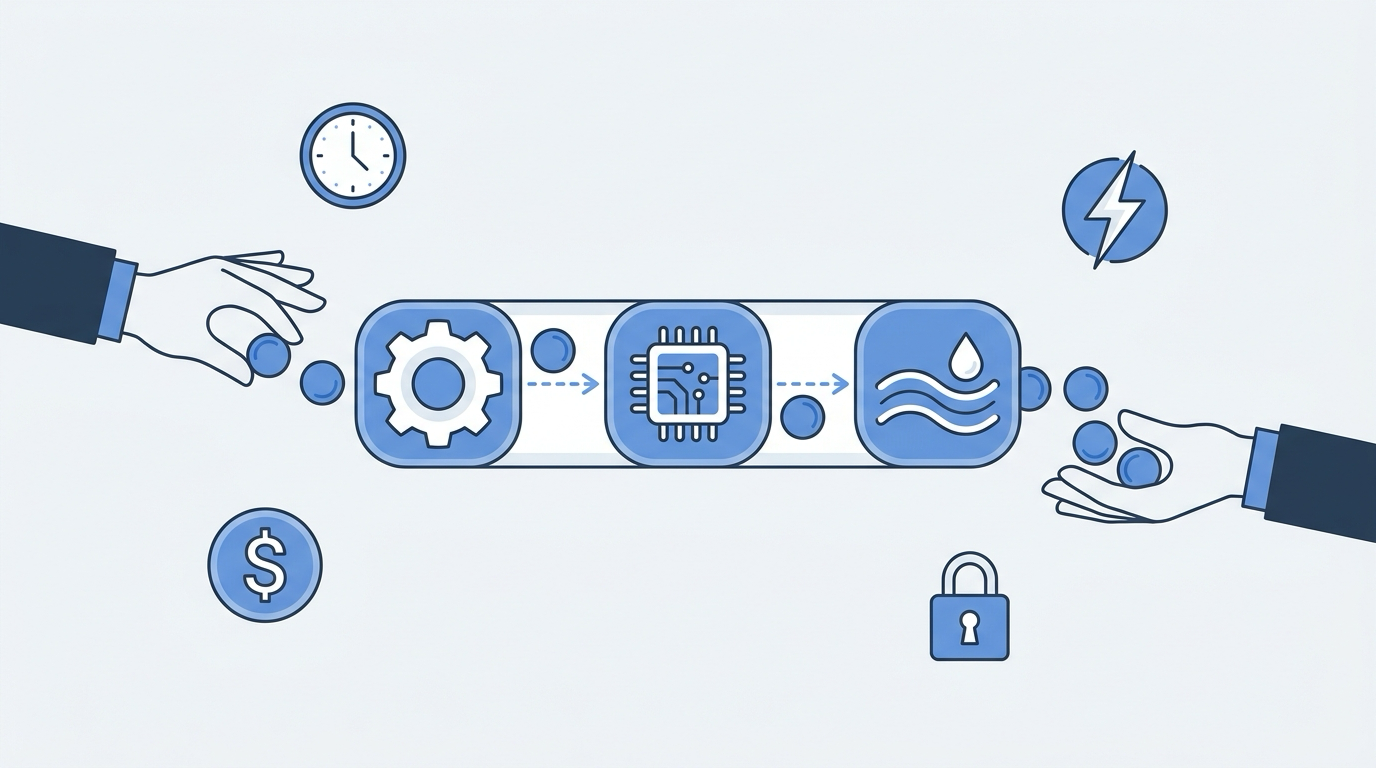
AIServing the Machine: How LLM Inference Runs at Planetary Scale
From PagedAttention to GB200 racks, from token economics to MCP — a systems engineer's tour of how frontier models serve millions of users simultaneously.
#llm-inference #gpu-architecture #vllm #pageattention #continuous-batching #mcp #api-design #quantization #speculative-decoding #ai-engineering -
 AI
AIPlatform Risk in AI: What the OpenClaw Ban Means for Your Stack
The OpenClaw ban reveals AI platform risk at scale. Six historical parallels, a 7-layer vendor lock-in mitigation stack, and what to do before the repricing hits.
#platform-risk #vendor-lock-in #ai-api #openclaw #anthropic #multi-provider #litellm #api-gateway #developer-tools #ai-engineering